
Große Sprachmodelle wie LLMs (Large Language Models), GPTs (Generative Pre-trained Transformers) und Foundation Models werfen neue Fragen auf. Müssen bald Übersetzer und Redakteure umlernen? In diesem Artikel beleuchten wir die Potenziale und Herausforderungen, die LLMs für diese Berufsgruppen mit sich bringen.
Wie künstliche Intelligenz Sprache lernt
Um die Funktionsweise von LLMs zu verstehen, lohnt sich ein Blick darauf, wie Menschen Sprachen lernen. Kinder pauken keine Vokabellisten oder Grammatikregeln. Stattdessen tauchen sie in die Sprache ein, hören Menschen zu und verknüpfen Wörter mit Handlungen, Gefühlen und Empfindungen. Nach und nach entsteht in ihrem Gehirn ein Modell, das Sprache strukturiert.
Ähnlich verhält es sich mit künstlicher Intelligenz, insbesondere mit LLMs. Ein solches Modell entsteht durch einen langen und rechenintensiven Lernprozess. Dabei werden Millionen von Texten verarbeitet und Parameter angepasst, damit das Modell Wörter in unterschiedlichen Kontexten korrekt voraussagen kann. So unterscheidet es beispielsweise zwischen dem Wort “Maus” im IT-Bereich und der “Maus” als Nagetier auf dem Bauernhof. Das Ergebnis dieses Lernprozesses ist ein Modell, das – wie etwa GPT-3 mit seinen 175 Milliarden Parametern [1] – diese vielen Wortbeziehungen durch Parameter festhält.
Gehirn versus Maschine: Parallelen und Unterschiede
Der Vergleich mit dem menschlichen Gehirn hinkt natürlich an einigen Stellen. Unser Gehirn ist weitaus komplexer und kann sich an neue Situationen wesentlich schneller anpassen. LLMs hingegen benötigen große Datenmengen und viel Rechenleistung, um zu lernen. Andererseits sind sie imstande, riesige Datenmengen zu verarbeiten, die für uns Menschen unüberschaubar wären. Hier liegt auch die große Stärke von LLMs: Sie können Muster in Daten erkennen, die uns verborgen bleiben.
Transformer und Attention Mechanism: Blick ins Innere der LLM-Maschine
Zwei wesentliche Faktoren tragen zum Sprachverständnis und zum großen Erfolg von LLMs bei:
- Die Netzwerkarchitektur Transformer: Sie beinhaltet den sogenannten “Aufmerksamkeitsmechanismus” (Attention Mechanism). Dieser Mechanismus ermöglicht es dem Modell, sich auf relevante Teile der Eingabe zu konzentrieren, indem die Kontextbeziehungen zwischen Wörtern berücksichtigt werden. Vereinfacht gesagt: So wie wir uns beim Zuhören auf bestimmte Aussagen konzentrieren und Nebengeräusche ausblenden, kann das Modell durch den Attention Mechanism wichtige Wörter in einem Satz stärker gewichten und unwichtige Informationen herausfiltern.
- Die Größe der Modelle: Je mehr Daten ein LLM verarbeitet, desto größer wird das Modell und desto besser kann es die Feinheiten menschlicher Sprache abbilden. LLMs wie GPT-3 und der noch größere Nachfolger GPT-4 mit seinen geschätzten 1,8 Billionen Parametern [1] decken eine Vielzahl von Sprachverwendungen ab und können dadurch menschliche Sprache immer natürlicher verarbeiten.
Wie entstehen neue Texte?
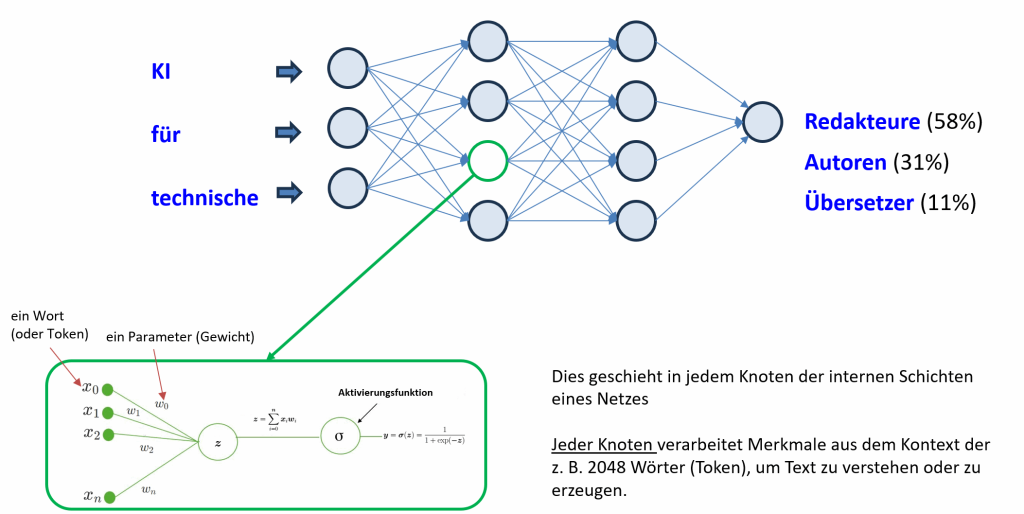
Nach dem Trainingsprozess werden LLMs zur Generierung neuer Texte eingesetzt. Vereinfacht gesagt, besteht das Modell aus Schichten, die jeweils für einen bestimmten Aspekt der Satzgenerierung zuständig sind. Wörter werden numerisch dargestellt und passen ihre Repräsentation an den aktuellen Kontext an, während sie sich von Schicht zu Schicht bewegen. Parameter wie numerische Gewichtungen und Bias [2] steuern diese kontextabhängigen Repräsentationen. So kann sich das Modell den Kontext merken und die Bedeutung von Wörtern besser verstehen. Trifft es beispielsweise auf das Wort “Maus”, analysiert das System die umliegenden Wörter in einem vordefinierten relativ großen Wortfenster. Informationen fließen von einer Schicht zur nächsten, bis die finale Ausgangsschicht eine mathematische Funktion namens “Softmax” einsetzt, um Berechnungen in Wahrscheinlichkeiten umzuwandeln. Basierend auf diesen Wahrscheinlichkeiten wählt das Modell dann das wahrscheinlichste nächste Wort aus und wiederholt diesen Vorgang für jedes Wort in der Sequenz, bis die Antwort vollständig ist.
Die Zukunft von LLMs in der Technischen Kommunikation und Übersetzung
Technische Redakteure und Übersetzer stehen durch den Einsatz von LLMs vor einem spannenden Wandel ihrer Arbeitswelt. Diese KI-Technologie eröffnet neue Möglichkeiten, die sowohl die Effizienz als auch die Qualität der Arbeit verbessern können.
Einsatzmöglichkeiten von LLMs in der Übersetzung
Neuronale maschinelle Übersetzung (NMÜ) hat in den letzten Jahren große Fortschritte gemacht und liefert bereits sehr gute Übersetzungen. Dennoch gibt es noch einige Bereiche, in denen LLMs Vorteile bieten können.
- Suche nach mehreren Übersetzungsvarianten: LLMs können Übersetzern helfen, verschiedene Übersetzungsmöglichkeiten für ein Wort oder eine Phrase zu finden. Dies ist besonders nützlich, wenn der Kontext unklar ist oder es mehrere mögliche Übersetzungen gibt, die unterschiedliche Bedeutungen haben.
- Anpassung an einen bestimmten Stil: LLMs können verwendet werden, um Übersetzungen an einen bestimmten Stil anzupassen. Dies kann z. B. der Fall sein, wenn die Übersetzung für eine bestimmte Zielgruppe oder für einen bestimmten Verwendungszweck erstellt wird.
- Inhaltliche (semantische) Überprüfung von Übersetzungen: LLMs können Übersetzern helfen, die inhaltliche Korrektheit von Übersetzungen zu überprüfen. Sie können z. B. erkennen, ob der Sinn des Originaltextes in der Übersetzung erhalten geblieben ist oder ob es semantische Fehler gibt.
Integration von LLMs in Übersetzungssysteme
Einige Entwickler von Übersetzungssoftware haben bereits damit begonnen, LLMs in ihre Systeme zu integrieren. Dies ermöglicht es Übersetzern, die Vorteile von LLMs direkt in ihrer Übersetzungsumgebung zu nutzen.
Einsatzmöglichkeiten in der Technischen Redaktion
- Automatische Erstellung von Inhalten: LLMs können technische Dokumentationen, Handbücher, FAQs und andere Inhalte auf Knopfdruck erstellen.
- Redaktionelle Unterstützung: LLMs können Redakteure bei der Recherche, Strukturierung und Formulierung von Inhalten unterstützen.
- Qualitätssicherung: LLMs können Grammatikfehler, Rechtschreibfehler und Inkonsistenzen in Texten erkennen und korrigieren.
- Multimodale Inhalte: LLMs können Text mit visuellen Elementen wie Bildern, Diagrammen und Videos kombinieren, um ansprechendere und verständlichere Inhalte zu erstellen.
Vorteile für Technische Redakteure und Übersetzer:
- Effizienzsteigerung: LLMs können repetitive Aufgaben automatisieren und somit Zeit und Ressourcen freigeben.
- Qualitätssteigerung: LLMs können helfen, die Qualität von Übersetzungen und technischen Dokumentationen zu verbessern.
- Neue Möglichkeiten: LLMs eröffnen neue Möglichkeiten für die Gestaltung und Erstellung von Inhalten.
Herausforderungen beim Einsatz von LLMs in der Technischen Kommunikation und Übersetzung
Qualitätssicherung und Revision
Die Integration von LLMs in den Arbeitsalltag von Technischen Redakteuren und Übersetzern bringt zwar neue Möglichkeiten mit sich, gleichzeitig stellt sie aber auch neue Herausforderungen dar. Die Qualitätssicherung und Revision der von LLMs generierten Inhalte ist unerlässlich, da diese Technologie noch einige Schwächen aufweist.
Typische Fehler von LLMs
- Erfinden von Informationen (Halluzinationen): LLMs neigen dazu, Informationen zu erfinden, insbesondere bei fachspezifischen Themen, die nicht zum Allgemeinwissen gehören. Sie präsentieren diese erfundenen Informationen mit einem hohen Grad an Überzeugungskraft, was die Gefahr von Fehlern und Missverständnissen erhöht.
- Falsche Umsetzung von Anweisungen: LLMs können Anweisungen falsch interpretieren oder missverstehen, was zu unerwünschten Ergebnissen führt, z. B. zu langen Texten, falschen Ausgabeformaten oder unvollständigen Inhalten.
- Ignorieren des Kontexts: Die generierten Antworten passen nicht immer zum spezifischen Kontext der Anfrage und können daher irrelevant oder unbrauchbar sein.
- Widersprüche: In einer Antwort können verschiedene Aussagen enthalten sein, die sich gegenseitig widersprechen.
- Unvollständige Antworten: Wichtige Informationen und Details können in der Antwort fehlen.
Schlussbemerkung
Generative KI wie LLMs haben das Potenzial, die Technische Kommunikation und Übersetzung grundlegend zu verändern. Die Technologie befindet sich noch in einem frühen Entwicklungsstadium, aber die Vorteile sind bereits deutlich erkennbar. Technische Redakteure und Übersetzer, die sich diese Technologie aneignen, werden in Zukunft einen entscheidenden Wettbewerbsvorteil haben.
Die D.O.G. GmbH befasst sich seit Jahren mit diesen Technologien und nutzt sie erfolgreich, um die Qualität unserer Übersetzungen zu optimieren. Davon können Sie profitieren.
Anmerkungen:
[1] Die Details der Modelle werden nicht offiziell veröffentlicht, aber einige Zahlen werden von Branchenexperten veröffentlicht, z. B. https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more-leaked/ (abgerufen am 22.12.2023).
[2] Im Bereich der künstlichen Intelligenz, insbesondere in neuronalen Netzen, sind “Gewichte” numerische Werte, die den Einfluss von Eingabedaten (z. B. Wörtern oder Phrasen) auf die Berechnungen des Netzes bestimmen. “Bias” sind zusätzliche Konstanten, die zur gewichteten Eingabe addiert werden, um dem Netz zu helfen, genauere Vorhersagen zu treffen.